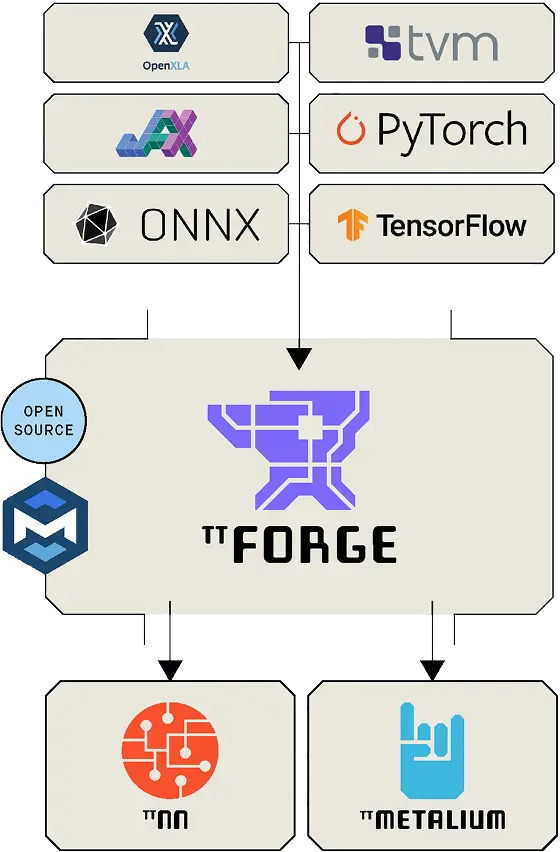
TT-Forge™는 Tenstorrent의 MLIR 기반 컴파일러로, 도메인별 컴파일러부터 맞춤형 커널 생성기에 이르기까지 다양한 ML 프레임워크와 호환되도록 설계되었습니다. TT-Forge™는 Tenstorrent의 기존 AI 소프트웨어 생태계와 기본적으로 통합되어 있어 손쉽게 개발할 수 있습니다.
TT-MLIR 컴파일러는 고수준 모델과 HPC 워크로드를 Tenstorrent 하드웨어 실행으로 연결하는 다리 역할을 합니다. MLIR은 PyTorch, OpenXLA, JAX와 같은 오픈소스 프레임워크와 완벽하게 통합되어 체계적인 컴파일 방식을 지원합니다. MLIR 생태계가 확장됨에 따라 향후 통합 가능성도 높아집니다.
혁신을 위한 설계
오픈 소스를 염두에 두고 개발된 TT-Forge™는 OpenXLA(JAX, Shardy), LLVM의 MLIR 및 torch-mlir, ONNX, TVM, PyTorch, TensorFlow 등 주요 기술과 통합됩니다. TT-Forge™는 개방형 표준 및 커뮤니티 기반 개발을 통해 고수준 프레임워크와 저수준 실행을 연결하여 AI 워크로드를 위한 유연하고 확장 가능한 기반을 제공합니다. 하드웨어 실행의 경우, TT-Forge™는 Tenstorrent의 AI 소프트웨어 스택을 활용하여 Tenstorrent 하드웨어에 맞춰 워크로드를 최적화합니다.
다중 프레임워크 프런트엔드 지원을 통한 일반적인 확장성
tt-torch
tt-torch는 MLIR 네이티브 오픈소스 PyTorch 2.X 및 torch-mlir 기반 프런트엔드입니다. tt-mlir에 안정적인 HLO(SHLO) 그래프를 제공합니다.
PT2.X 컴파일을 통해 PyTorch 모델을 수집하고 torch-mlir(ONNX->SHLO)을 통해 ONNX 모델을 수집하는 것을 지원합니다.
또한 PyTorch 그래프를 개별 작업으로 분해하여 병렬화된 버그나 누락된 작업을 쉽게 발견할 수 있습니다.
tt-forge-Fe
TT-Forge-FE는 딥 러닝 모델을 위한 계산 그래프를 최적화하고 변환하여 성능과 효율성을 향상시키도록 설계된 그래프 컴파일러입니다.
TVM(tt-tvm)을 통해 PyTorch, ONNX, TensorFlow 및 유사한 ML 프레임워크의 수집을 지원합니다.
TVM IR을 기반으로 다양한 프레임워크의 그래프를 개별 작업으로 분해하여 모델 구축 작업을 데이터 중심으로 수행할 수 있습니다.
tt-xla
tt-xla는 PJRT 인터페이스를 활용하여 JAX(그리고 향후 다른 프레임워크), tt-mlir 및 Tenstorrent 하드웨어를 통합합니다.
tt-mlir 컴파일러에 StableHLO(SHLO) 그래프를 제공하여 jit 컴파일을 통해 JAX 모델을 수집할 수 있도록 지원합니다.
tt-xla 플러그인은 JAX에 기본적으로 로드되어 tt-mlir 컴파일러와 런타임으로 JAX 모델을 컴파일하고 실행합니다.
특징
성능
최적화된 컴파일 및 커스텀 언어(TTIR, TTNN, TTKernel)를 통해 효율적인 실행이 가능해져 Tenstorrent 하드웨어에서 추론 및 학습 성능이 극대화됩니다. tt-explorer를 통해 성능 최적화가 간소화되었습니다.
범용성
TT-Forge™는 여러 ML 프레임워크(PyTorch, JAX, TensorFlow, ONNX)와 MLIR 방언을 지원하여 다양한 AI 워크로드에서 광범위한 호환성과 유연성을 보장하고 향후 프레임워크로 확장할 수 있는 기능을 제공합니다.
도구
Tenstorrent 툴체인은 ML 모델 컴파일, 최적화 및 실행을 간소화합니다. MLIR 기반 컴파일부터 런타임 검사까지, 이러한 툴은 Tenstorrent 하드웨어에서 효율적인 개발, 디버깅 및 성능 튜닝을 지원합니다.